Hyper-Personalization Marketing With Live Signals
Most B2B SaaS teams have tried personalisation. They have segments in HubSpot. They have personalised subject lines. They have industry-specific landing page variants. And most of them will tell you the same thing privately: it still feels thin.
It feels thin because it is. Not because the marketer is doing it wrong, but because segments are the wrong foundation for personalisation.
A segment describes where a buyer was when the list was built. It does not describe where they are right now. A buyer who downloaded a pricing comparison guide three days ago is in a different moment than when they signed up for the newsletter six weeks ago. The segment treats them the same. The outreach they receive is calibrated to a moment that has already passed.
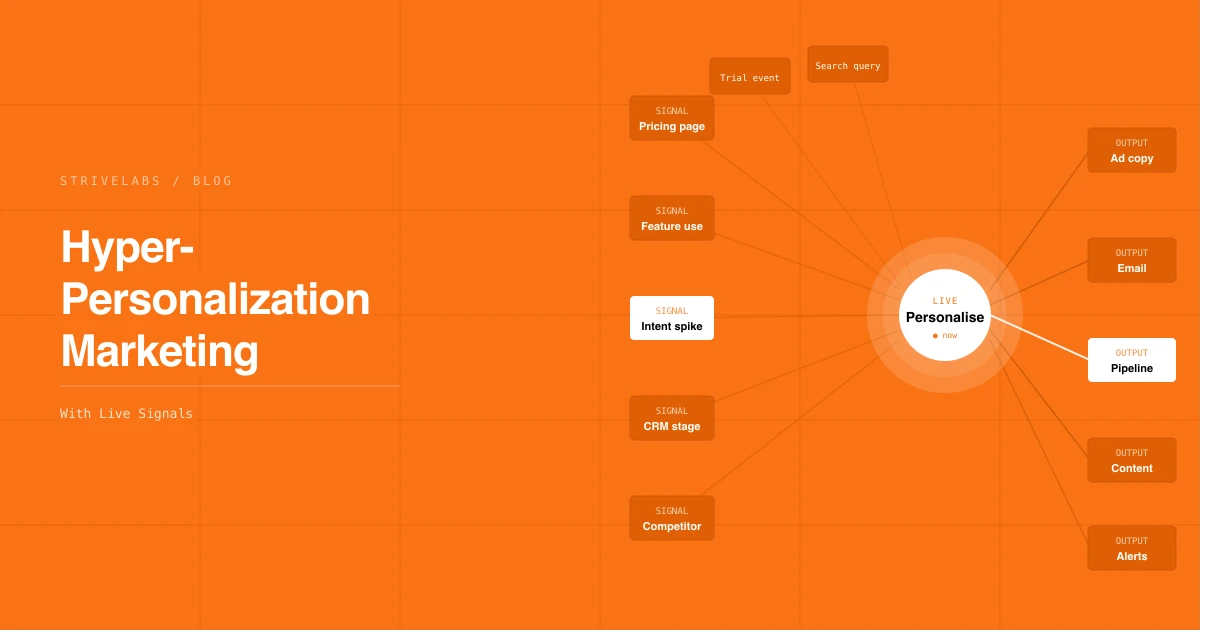
Hyper-personalization marketing solves this by replacing static lists with live signals. Instead of personalising from a segment definition, the Agentic Marketing Engine personalises from what is actually happening, pipeline stage changes in HubSpot, product usage events, content engagement signals in GA4, ad interaction patterns across Google and LinkedIn, right now, not last month.
Only 15% of CMOs believe they are on track to deliver personalisation at scale despite it being the most cited growth priority in B2B marketing. The gap is not ambition. It is architecture. Signal-based personalisation closes that gap, and it does not require a CDP, a data engineering team, or an 18-month implementation.
This post covers the three most important agentic personalisation scenarios for a B2B SaaS team, the data connections that make them possible, and how Strivelabs delivers them without rebuilding your stack.
At a Glance
-
Segment-based personalisation has a structural ceiling. Segments are snapshots. Buyers move. The outreach stays calibrated to the wrong moment.
-
Signal-based hyper-personalization marketing responds to what buyers are doing right now — pipeline stage changes, product events, content engagement, ad interactions.
-
Three signals drive the highest pipeline impact for B2B SaaS: pipeline stage signals from HubSpot, product usage signals, and content engagement signals from GA4 and Search Console.
-
Human approval stays at every step. The agent reads the signal, generates the personalised action, and waits for sign-off before anything reaches a buyer.
-
No CDP required. Strivelabs connects HubSpot, GA4, Google Ads and LinkedIn directly.
Why Hyper Personalization Marketing Fails Before It Starts for Most B2B SaaS Teams
The failure is not a tool problem. Every B2B SaaS marketing team has enough tools. The failure is a timing problem.
Personalisation that runs from segments is always calibrated to the past. The segment was built last quarter. The buyer's behaviour changed last week. The outreach they receive today reflects neither.
B2B buying committees now average 11.2 stakeholders for deals over $50k, with sales cycles running 121 days for mid-market. Across a 121-day cycle with 11 stakeholders, a buyer moves through multiple distinct moments, awareness, evaluation, comparison, commercial discussion. Each moment has a different information needed. A segment assigns them one bucket and keeps them there regardless of which moment they are actually in.
The result is what every B2B SaaS marketer privately knows: personalisation that puts the company name in the subject line and the industry in the first sentence, then delivers content that could have been sent to anyone at any point in the cycle.
The Segment Ceiling — Why Static Lists Are the Wrong Foundation for Hyper Personalization
Here is the specific way segments fail, and why it is structural not fixable:
Segments are built from historical data. A buyer is placed in a segment based on what they did before they were segmented. From that point forward, new behaviour does not automatically update their segment membership. A buyer who was "awareness stage" three weeks ago and visited the pricing page twice yesterday is still in the awareness nurture sequence unless someone manually updates the segment rule.
Segments collapse individual behaviour into group averages. Everyone in the "mid-market SaaS" segment receives the same outreach. The buyer who visited the pricing page yesterday and the buyer who has not logged into a trial in two weeks are treated identically because they share firmographic characteristics.
Segments cannot respond to in-the-moment signals. A trial user who just hit the activation milestone for the third time this week is showing a buying signal right now. A segment cannot detect it, cannot respond to it, and cannot deliver the message that matches that specific moment.
| Segment-based personalisation | Signal-based hyper-personalization marketing | |
|---|---|---|
| Data source | Historical lists | Live events |
| Update frequency | Manual or scheduled | Continuous |
| Personalisation unit | Group | Individual |
| Responds to behaviour | No | Yes |
| Pipeline connection | Assumed | Measured |
| Setup requirement | Segment rules | Connected data sources |
Better decisions start with better infrastructure.
Most mid-market teams pick a channel and hope. Strivelabs gives you the data to know, and the infrastructure to act on it.
Book a Demo →
What Signal-Based Hyper Personalization Marketing Actually Looks Like
Signal-based personalisation reads live events and acts on them in near real-time. Three types of signals drive the most pipeline impact for B2B SaaS teams:
Pipeline signals — changes in HubSpot deal stage, contact status, recent sales activity. These show where the buyer is in the commercial conversation right now.
Behavioural signals — product usage events, trial milestones, feature activation, session patterns. These show what the buyer is doing inside the product right now.
Content and intent signals — which pages a buyer visited, which search terms brought them to the site, which content they engaged with deeply. These show what the buyer is trying to understand right now.
The Agentic Marketing Engine reads all three signal types continuously from HubSpot, GA4, Google Ads, LinkedIn Ads and Search Console. When a signal fires, a pipeline stage change, a product milestone, a pricing page visit, the engine identifies the personalisation opportunity, generates the recommended action, and queues it for approval. The marketer reviews and approves before anything reaches a buyer.
Three Personalisation Scenarios That Are Only Possible With Agentic AI
These are not hypothetical. They are specific scenarios where segment-based personalisation structurally cannot respond and signal-based personalisation can.
Scenario 1 — Personalising by where the buyer is in the pipeline right now, not where they were when you built the segment
The current situation without signal-based personalisation:
A buyer moves from MQL to opportunity in HubSpot on Tuesday. Your marketing automation has them in a 14-day awareness nurture sequence. They receive a top-of-funnel educational email on Wednesday, because that is where they were in the sequence, not where they are in the buying cycle. Your sales rep is in their inbox the same day with a commercial conversation. The marketing outreach and the sales outreach are completely disconnected. The buyer experiences cognitive dissonance. The marketing spend on that contact is now actively working against the sales motion.
What the agent does:
The Strivelabs agent reads the HubSpot pipeline stage change in real time. It identifies that this contact is now in active commercial discussion. It generates two recommended actions: suppress the awareness nurture sequence, and update the LinkedIn ad audience to exclude this contact from top-of-funnel creative. It queues both for approval with its reasoning attached. The marketer approves in thirty seconds. The buyer never receives the disconnected awareness email. The LinkedIn impression that would have shown them an awareness ad instead does not fire.
Why this matters for pipeline:
Wasted spend on buyers already in the pipeline is one of the most common and most invisible budget leaks in B2B SaaS marketing. For a team spending $15k per month on LinkedIn, suppressing in-pipeline contacts from awareness targeting typically recovers 8-15% of that spend. That is not a marginal optimization. It is a structural fix that only becomes visible when pipeline data and ad platform data are connected in the same system.
Scenario 2 — Personalising paid ads from what the buyer just did in your product or on your site
The current situation without signal-based personalisation:
A free trial user activates the core feature of your product for the third time this week. That is a strong buying signal, they are finding value and they are engaged. Your current ad targeting does not know this happened. They continue to see the same awareness creative as every other trial user regardless of their activation level. An opportunity to reinforce the value they just experienced, introduce the upgrade path, and accelerate the conversion decision goes undetected and unaddressed.
What the agent does:
The engine reads the product usage event from HubSpot, the activation milestone triggered three times in seven days. It identifies this as a high-intent signal. It generates a recommended action: update the Google Ads remarketing audience to show this contact upgrade-focused creative rather than awareness creative. It drafts the copy variant that references feature adoption specifically. It queues both the audience update and the copy variant for approval. The marketer reviews, adjusts the copy if it needs a brand voice correction, and approves. The next ad this contact sees is calibrated to where they actually are, not where a segment assumed they were.
Why this matters for pipeline:
Timing personalisation to product behaviour consistently outperforms time-based sequences. A buyer who has activated a core feature three times is not at the same moment as a buyer who signed up last week and has not logged in since. The gap between those two moments is invisible to segment-based personalisation. It is the primary input for signal-based personalisation.
Scenario 3 — Personalising content recommendations from what is driving pipeline this week, not last quarter
The current situation without signal-based personalisation:
Your content team publishes based on a quarterly editorial calendar. The calendar was built on keyword research conducted three months ago. This week, three deals in your pipeline have mentioned a specific competitor in sales calls. Your sales team is fielding questions about a capability gap your competitor claims to have. The editorial calendar has no mechanism to detect this pattern and no way to surface it as a content priority. The blog posts going live this week are on topics that were relevant three months ago.
What the agent does:
The engine reads Search Console data showing a rise in competitor comparison queries landing on your site. It cross-references with HubSpot deal notes where the competitor name appears. It identifies a content signal: there is a buyer question in the market right now that your current content does not fully answer and your competitors are showing up for. It generates a recommended action: a content brief targeting the comparison keyword, structured to answer the specific objection appearing in sales calls. It queues the brief for the content marketer's review. The post that addresses the current market conversation is briefed this week, not next quarter.
Why this matters for pipeline:
Top-quartile SaaS marketing teams attribute 41% of the qualified pipeline to organic search, content and AEO. Content that answers the question a buyer has right now closes deals. Content that answers the question a buyer had three months ago keeps ranking but stops influencing the pipeline. The difference is the signal connection between what is happening in sales conversations and what the content team is writing about.
What Hyper Personalization Marketing Requires — the Data Connections That Make It Possible
You do not need a CDP. You do not need a data warehouse. You need four connected data sources and clean identity matching between them.
HubSpot pipeline data. Deal stage, contact status, recent activity, deal value. This is the source of pipeline signals. Without it, the engine cannot connect marketing actions to commercial moments.
Product usage events. Trial activations, feature usage, milestone completions. These are the strongest buying signals most B2B SaaS teams never act on because the data sits in a product analytics tool that has never been connected to marketing. A simple HubSpot integration or webhook from your product database is sufficient.
Ad platform data. Google Ads, LinkedIn Ads, Meta Ads, connected via OAuth. The engine needs read/write access to update audiences and creative in response to signals.
GA4 and Search Console. Content engagement data, search term data, landing page performance. The source of intent signals — what buyers are searching for and reading before they fill in a form.
Identity matching across these four sources, connecting an anonymous visitor to a known HubSpot contact, is the foundational requirement. Without it the signals exist but cannot be actioned at the individual level. With it, every signal becomes a personalisation trigger.
Strivelabs connects all four via OAuth in under five minutes. No engineering work. No data warehouse required. The closed loop from signal to action is built into the integration layer.
How the Agentic Marketing Engine Runs Personalisation Continuously Without a CDP
Most enterprise personalisation solutions require a CDP as the central data layer. The CDP ingests all sources, builds unified profiles, and feeds downstream personalisation tools. That architecture requires a data engineering team to build and maintain. Implementation takes months. The cost is significant.
Strivelabs' architecture is different. The Agentic Marketing Engine connects directly to the source systems, HubSpot, GA4, Google Ads, LinkedIn, Search Console, and maintains the unified profile internally as a semantic layer specific to each customer. Strivelabs builds organisational knowledge across your ICP, goals, attribution patterns, and tribal knowledge from Slack and Zoom calls. That semantic layer is what enables personalisation that is specific to your business, not generic AI output applied to your data.
The three scenarios above run automatically once the data sources are connected. The engine monitors all four signal types continuously. When a signal fires, a pipeline stage change, a product milestone, a content engagement pattern, it identifies the personalisation opportunity, generates the recommended action with its reasoning, and queues it for approval.
The human-in-the-loop principle applies throughout. Every personalisation action, audience update, copy variant, content brief, requires the marketer's approval before it reaches a buyer. The agent personalises at the signal level. The marketer approves at the judgment level. Brand voice, competitive claims, strategic priorities, these stay with the marketer.
The result: hyper-personalization marketing at scale for a two-person B2B SaaS marketing team, running across paid, SEO and CRM simultaneously, without a CDP, without a data engineering team, and without manual segment management.
The marketing engineer function, delivered as software.
See how Strivelabs gives mid-market teams the operational capacity without the hiring cost.
Explore Strivelabs →
Frequently Asked Questions (FAQs)
What is hyper-personalization in marketing?
Hyper-personalization uses live behavioural signals, not static segments, to tailor messaging to individual buyers based on what they are doing right now. In B2B SaaS, this means personalising from pipeline stage changes in HubSpot, product usage events, and content engagement in GA4 rather than from demographic or firmographic list membership.
What is segment-of-one marketing?
Segment-of-one is the goal of treating each buyer as an individual rather than a group member. It requires live signal reading rather than list-based segmentation because buyer behaviour changes faster than segments can be updated. Agentic AI makes segment-of-one achievable at scale by automating signal detection and personalisation execution.
How does agentic AI enable personalisation at scale?
Agentic AI reads signals from multiple data sources continuously, HubSpot pipeline data, product usage events, ad interactions, content engagement. When a signal fires, it generates a personalised recommended action and queues it for approval. This replaces manual segment management with automated signal response, making individual-level personalisation possible across thousands of contacts simultaneously.
What is the difference between segment-based and signal-based personalisation?
Segment-based personalisation puts buyers into groups based on historical characteristics and sends the same outreach to everyone in the group. Signal-based personalisation responds to what a specific buyer is doing right now, a pipeline stage change, a product milestone, a pricing page visit. The difference is the gap between a message calibrated to the past and a message calibrated to the present moment.
Do I need a CDP for agentic personalisation?
No. Strivelabs connects directly to HubSpot, GA4, Google Ads, LinkedIn Ads and Search Console via OAuth. The Agentic Marketing Engine maintains a unified semantic layer internally. No CDP, no data warehouse, no engineering work required. Most teams are fully connected within a single meeting.
How does Strivelabs personalise across paid and CRM simultaneously?
Strivelabs connects HubSpot pipeline data and ad platform audiences in the same system. When a contact moves the pipeline stage in HubSpot, the engine updates the corresponding ad audience automatically, suppressing awareness creative for in-pipeline contacts, serving upgrade creative for high-activation trial users. The marketer approves the audience update before it goes live.
Related Posts

The AI Attribution Gap: AI Search Visibility for B2B SaaS
51% of B2B buyers start vendor research in AI not Google. 90% of brands have zero AI search mentions. Here is what drives citation frequency and how to connect it to pipeline.
How to Find and Eliminate Wasted Ad Spend Automatically
Your ad dashboards show clicks. They cannot show which campaigns are generating zero pipeline. Strivelabs connects Google Ads, LinkedIn and HubSpot to find and eliminate wasted spend automatically.
How to Get Cited in ChatGPT, Perplexity and AI Overviews
Getting cited in ChatGPT, Perplexity and AI Overviews requires six specific signals. Here is how Strivelabs tracks and improves your citation frequency automatically.